 Envel Le Hir
Envel Le HirHow many properties are created on Wikidata each month?
I was asked if there was a slowdown or even a stop in property creations on Wikidata.
The first idea was to make a SPARQL query on the Wikidata Query Service. A quick check shows that the date of creation of a property is not stored there, only the date of its last modification:
SELECT * {
wd:P31 ?property ?value .
FILTER(DATATYPE(?value) = xsd:dateTime) .
}
There is of course a feature request for that (T151539), opened in 2016.
Wikidata relies on Mediawiki, the wiki software used by most projects of the Wikimedia Foundation. Each object (an item, a property or a lexeme) is stored as a page in Mediawiki. So let’s query its SQL database, using Quarry:
SELECT `date_creation`, COUNT(*) AS `count` FROM ( SELECT MIN(SUBSTRING(`rev_timestamp`, 1, 6)) AS `date_creation` FROM `page`, `revision` WHERE `page`.`page_id` = `revision`.`rev_page` AND `page`.`page_namespace` = 120 GROUP BY `page`.`page_title` ) `a` GROUP BY `date_creation` ORDER BY `date_creation` DESC
Properties are stored in a dedicated namespace, which id is 120 (line 5). For each page of a property, we retrieve the first date creation of its revisions (subquery). Then, we aggregate by month to get the number of properties created each month. Note that this method provides statistics only about properties that still exist.
Finally, we can make a graph:
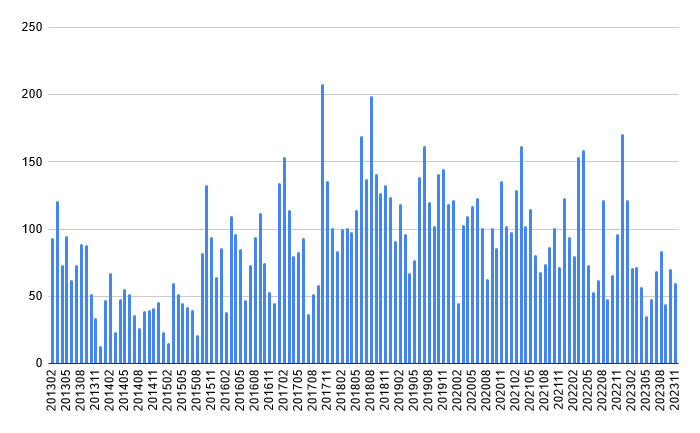
While it’s not as huge as in 2018, property creations is still active on Wikidata.
Using Wikidata to check votes of the Wikimedia Foundation board election
Seats of the Wikimedia Foundation Board of Trustees are regularly partially renewed by the community. In 2022, two seats are at stake, in a complex procedure, including a community vote that took place from August 23 to September 6. The list of voters is public, with many details: date of vote, username of the voter, if the vote has been cancelled (because the same account voted a second time, or because the vote has been manually struck).
I wrote a set of scripts to gather data and to compute statistics about this election. The first goal was to automatically check some rules of the voter eligibility guidelines, like that a bot account did not vote (there was at least one, and their vote has been struck after it was reported to the elections committee). Let’s see how we can use Wikidata to perform some basic checks.
On Wikidata, the property Wikimedia username (P4174) links an item to a Wikimedia account. After retrieving the list of voters, it’s easy to check some rules with the related data on Wikidata.
A first idea was to check if a vote was linked to someone supposed to be dead (they are about one hundred wikimedians with a date of death on Wikidata). None was found.
Another idea was to check if someone used several accounts to vote. People can have several Wikimedia accounts for legitimate reasons: a separate bot account, a separate account for each employer when their work is related to Wikimedia, for privacy concerns, and so on (example). With the list of voters, it was checked if several usernames belong to the same item on Wikidata (and so to the same person).
With this method, two voting accounts were found to belong to the same person (Q78170633 is the related item on Wikidata): Masssly (their personal account, voted on 5 September 2022) and Mohammed Sadat (WMDE) (their account as an employee of Wikimedia Deutschland, voted on 26 August 2022). On the one hand, this is surprising because they are a member of the elections committee, supposed to enforce the voter eligibility guidelines, on the other hand, it’s not the first time they cause concerns during an election (fortunately smoothly solved by the community in that case). The issue has been publicly reported on September 7. To my knowledge, it was not followed by any action nor comment; in the meantime, several votes were struck on similar cases.
While these methods allowed to find some fraud, it is very limited: a lot of wikimedians don’t have a Wikidata item, and a lot more don’t have all their usernames on their Wikidata item.
Don’t hesitate to contact me to discuss or to suggest improvements to the project.
Using tfsl to clean grammatical features on Wikidata lexemes
tfsl
tfsl is a Python framework written by Mahir256 to interact with lexicographical data on Wikidata. It has several cool features:
- A great documentation.
- A simple but effective data model to retrieve, manipulate and update lexemes.
At the moment, it has some limitations:
- The framework is not packaged, so you have to manually integrate it into your project.
- It is not possible to use the bot flag.
Grammatical features
A lexeme is linked to a set of forms. These forms can usually be discriminated by their grammatical features. For instance, the lexeme L7 has two forms that can be distinguished by their number: cat (singular) and cats (plural). These grammatical features can be a combination of several traits. For instance, the lexeme L11987 has four forms, distinguished by their gender and their number, like banal, which is masculine and singular, or banales, which is feminine and plural.
It is a best practice to use atomic values for each trait of these grammatical features (easier querying, fewer items to maintain, etc.).
Let’s clean grammatical features on French lexemes!
Finding lexemes with issues
First, we list some items mixing several grammatical features on Wikidata. A key represents a mixed item, like masculine singular (Q47088290), and the values are the items by which it should be replaced, like masculine (Q499327) and singular (Q110786).
Then, we build a SPARQL query to find French lexemes using these mixed items as grammatical features in their forms:
SELECT DISTINCT ?lexeme {
?lexeme dct:language wd:Q150 ; ontolex:lexicalForm/wikibase:grammaticalFeature ?feature .
VALUES ?feature { wd:Q47088290 wd:Q47088292 wd:Q47088293 wd:Q47088295 }
}
Cleaning lexemes
We retrieve each lexeme with tfsl, for instance:
lexeme = tfsl.L('L11987')
Then, we clean the forms of the lexeme:
for form in lexeme.forms:
for feature in replacements:
if feature in form.features:
form.features.remove(feature)
form.features.update(replacements[feature])
Finally, we update the lexeme on Wikidata:
session = tfsl.WikibaseSession('username', 'password')
session.push(lexeme, 'cleaning grammatical features')
You can see the related diff on Wikidata.
Summary
In a nutshell, we were able to easily clean grammatical features on French lexemes with a few lines of code (the full script is available) using tfsl. While it still has some limitations at the moment, this framework can become in the near future the best way to interact programmatically with lexicographical data on Wikidata.