 Envel Le Hir
Envel Le HirA tool to estimate the gender gap in Wikidata and Wikipedia
A new version of this tool was released and this article is out of date. You can find detailed information about the new version in this blog post: Denelezh 2.0, a transitional version.
Context
Last November, for the 10th anniversary of Wiki Brest, Florence Devouard gave a talk about wikis (« Les wikis et vous ? », “Wikis and you”). She of course mentioned the gender gap in Wikipedia, that occurs on many levels: biographies in Wikipedia are mainly about men, Wikipedia contributors are mainly men (the audience that day could not deny that with the row of Wikimedians composed exclusively of men), etc.
One difficulty is to measure those gaps and how they differ from the gender gap in real world. As I contribute about French politicians on Wikidata, I had one example in mind where the gap in Wikipedia biographies was only a reflect of the real world: in French National Assembly, there are only 27 % of women and the gap has been slowly decreasing for only 20 years. But I had no clue for other professions or countries.
Wikidata is the central repository of Wikimedia projects for structured data. As of March 2017, it holds data about 25 million concepts (called items), including more than 3 million notable people. An idea was to use this huge content to have more statistics about gender gap. Three weeks ago, I started to work on a reporting tool to automatically compute data from Wikidata and display statistics about the gender gap: Gender Gap in Wikidata. The tool is available since March 8, 2017.
Features
The tool provides indicators about:
- Humans in Wikidata,
- Humans in Wikidata linked to at least one wikipedia (it can be seen as the number of notable people, even though each wikipedia has its own notability rules),
- Links to wikipedias for humans in Wikidata (it can be seen as the number of biographies in wikipedias).
For each set, it displays data for three subsets: women, men and others. Others subset gathers humans whose gender is known but neither female nor male.
![]()
Each set can be aggregated by year of birth, country of citizenship and occupation, with all possible combinations.
Aggregated data can be downloaded as a CSV file from the About page.
An important point is that not all humans in Wikidata are used to produce these statistics. To sum up, only humans with gender, year of birth and country of citizenship are used. This is explained in the following section.
Methodology
Dump
Each week, Wikidata provides a full copy of its database (called dump). In the following sections, figures were made using the dump of March 6th 2017.
In a dump, data is structured in statements. A statement is a triplet item–property–value. An item can have several values for a given property. For example, a person can have more than one occupation. Another example is when sources disagree about an information.
Each statement has a rank: preferred, normal, or deprecated. The tool ignores statements with deprecated rank. When it looks for a single value of a property, it is done by looking first in the subset of statements with preferred rank for this property. If and only if this subset is empty, it looks in the subset of statements with normal rank.
Human
Rule 0: A human is an item with a single value of property instance of, equal to human.
There are 3,400,591 humans.
Gender
The tool aggregates humans by gender, in 3 subsets (females, males, and others). Each value which differs from female and male is considered as other.
Rule 1: Each human has a single value of property gender.
This has two effects:
- Humans with no gender (227,426) are discarded.
- Humans with more than one gender are discarded. It makes analysis easier (no subset shares element with another subset). It filters only 207 people, which is light compared to the set of humans with exactly one gender (3,172,958), but significant compared to the final size of others subset (156). Maybe those humans should be considered as others, instead of removing them?
Property values are not checked, meaning that some may be false. In the dump, gender values are:
| Value | Count |
|---|---|
| male | 2,645,020 |
| female | 527,692 |
| transgender female | 153 |
| transgender male | 45 |
| intersex | 24 |
| genderqueer | 15 |
| male organism | 4 |
| female organism | 2 |
| Hombre | 1 |
| kathoey | 1 |
| transgender | 1 |
There are only 7 obvious errors:
- Female organism and male organism are values reserved for non-human organisms,
- Hombre is an American magazine, which name means man in Spanish.
Other errors can still exist (for example, a man with female for its gender).
Year of birth
The tool aggregates humans by year of birth.
Rule 2a: Each human has a single value for its year of birth.
There are 2,635,804 humans with a single value for the property date of birth. When there are more than one value for it, the tool checks that all the values have at least yearly precision and that the year is the same for all the values. It allows to keep 9,204 extra humans. There are 2,617,321 humans with a year of birth.
Rule 2b: Year of birth can not be before 1600.
This is done to avoid working on nearly-empty sets. It filters 60,730 people.
Rule 2c: Year of birth can not be after the year of the dump.
This is done to remove wrong data (we don’t have time travel yet). It filters 1 person.
The tool assumes that all dates are represented in Gregorian and Julian calendars, without normalizing them.
Country of citizenship
The tool aggregates humans by country of citizenship.
Rule 3a: Each human has a single value for property country of citizenship.
Like rule 1, rule 3 has two effects:
- Humans with no country of citizenship (1,331,299) are discarded.
- Humans with more than one country of citizenship are discarded. It filters 77,156 people.
There are 1,992,136 humans with one country of citizenship.
Rule 3b: Humans from countries with less than 100 people are removed.
This rules is applied after all the other rules. It removes only 4,179 humans, including a lot of garbage (like values French instead of France).
Selection
Only humans meeting all preceding rules are kept. The goal is to remove people with few data (and therefore likely of poor quality). In the table below, you can see cardinalities of humans sets respecting each group of rules:
| Set | Cardinality | Ratio |
|---|---|---|
| Rule 0 (human) | 3,400,591 | 100.0 % |
| Rule 1 (gender) | 3,172,958 | 93.3 % |
| Rules 2a, 2b and 2c (year of birth) | 2,556,591 | 75.2 % |
| Rule 3a (country of citizenship) | 1,992,136 | 58.6 % |
| Rules 0 to 3b | 1,730,427 | 50.9 % |
In the end, 1,730,427 humans are kept, with 208 distinct countries of citizenship.
Occupations
The tool aggregates humans by occupation. All occupations with preferred and normal ranks are kept. A same person can therefore have 0 to several occupations.
Rules 4: Occupations with less than 100 people are removed.
This rule removes 4,577 distinct occupations. In the end, there are 638 distinct occupations. 2,154,559 occupations are associated to 1,730,427 people (1.25 occupations per capita). There are 240,723 people without occupation.
Analysis
The following is not an analysis of the data provided by the tool, but some elements that you should take into account before using it.
Gender gap over time
For humans born before 1850, gender gap is roughly stable, as women represent around 5 % of the population selected in Wikidata. For humans born after 1850, gender gap is regularly reducing, but still exists and remains important. You can see below the relative gender gap by decade of birth, from 1800 to 1999 (women are in orange on the left, men in green on the right):

Country of citizenship
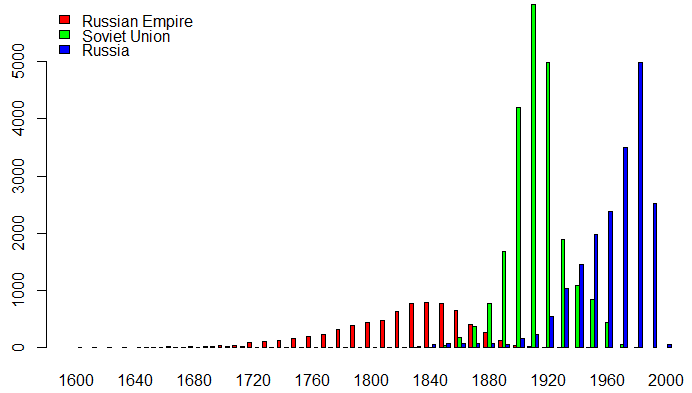
You can’t directly compare figures from two countries as they don’t have the same history. For example, Russian Empire existed from 1721 to 1917, Soviet Union from 1922 to 1991 and Russia since 1990. As we saw before, gender gap is reducing over time after 1850, so you can’t directly compare those countries. You can see below the number of people born by decade, for those three countries of citizenship, in the selected set:
Occupation
The tool does not take into account inheritance offered by property subclass of. For example, someone with screenwriter occupation will not appear in the subset of writer if this second occupation is not explicitly stated.
Position held
I made a quick test in order to use position held property in the same way as occupation. It seemed less interesting as it is essentially positions as member of parliaments in North-American and European countries. A dedicated work for this subject should be done (I started for France).
Let’s play!
As you can see, there are a lot of tracks to improve or analyze data on gender gap in Wikidata and Wikipedia. If you don’t know where to start, a simple way to improve data about humans in Wikidata is to play Wikidata games, with dedicated games for each property: Person, Gender, Date (of birth), Country of citizenship, and Occupation.
Technical overview
The tool is a small project, that you can divide in three parts:
- A Java project. It uses Wikidata Toolkit to extract data from Wikidata weekly JSON dumps. It produces two CSV files with data about people and their occupations.
- A PHP script (mainly SQL and SPARQL queries). It loads data into a relational database and aggregates it. It also fetches countries and occupations labels from Wikidata Query Service.
- A website to display aggregated data.