 Envel Le Hir
Envel Le HirAlignement des jeux vidéo de la BnF avec Wikidata grâce à Dataiku DSS
You can read this post in English: Matching BnF and Wikidata video games using Dataiku DSS.
Si les collections de la Bibliothèque nationale de France (BnF) comportent évidemment de nombreux livres, imprimés, périodiques ou encore manuscrits, elles se composent également d’éléments issus de techniques plus récentes, comme les jeux vidéo. D’après son point d’accès SPARQL, le catalogue général de la BnF a des informations sur un peu plus de 4000 jeux vidéo. Dans le même temps, Wikidata possède des informations sur plus de 36 000 jeux vidéo, dont seulement 60 (début février 2019) ont un lien vers une notice de la BnF !
Dans ce billet, on va voir comment améliorer ce maillage à l’aide du logiciel Dataiku Data Science Studio (Dataiku DSS), l’objectif étant d’ajouter, de manière correcte, le maximum d’identifiants BnF aux éléments Wikidata sur les jeux vidéo.
Installation de Dataiku DSS
L’installation et la prise en main de Dataiku DSS sont en-dehors du cadre de ce billet ; voici toutefois quelques informations qui pourront vous être utiles.
Vous pouvez télécharger la version gratuite de Dataiku DSS, amplement suffisante dans notre cas, sur le site de Dataiku, en suivant les instructions adaptées à votre environnement (par exemple, j’utilise Dataiku DSS dans la machine virtuelle proposée, en y accédant par mon navigateur web préféré).
L’installation du plugin SPARQL (présentation détaillée dans ce billet, en anglais) est nécessaire :
- Téléchargez la dernière version (code source au format .zip).
- Une fois connecté à votre instance Dataiku DSS, allez dans le menu Administration, puis dans l’onglet Plugins et enfin dans le sous-onglet Advanced ; téléversez le plugin.
- On vous demande de créer un code environment ; laissez les options par défaut et cliquez sur CREATE. L’opération peut prendre quelques dizaines de secondes. Rechargez ensuite l’interface de Dataiku DSS en appuyant sur F5.
En ce qui concerne la prise en main de Dataiku DSS, suivre les deux premiers tutoriels proposés par Dataiku devrait être suffisant pour comprendre ce billet.
Pour la suite, on suppose que vous avez créé un nouveau projet dans Dataiku DSS.
Données de Wikidata
Import des données
On récupère les jeux vidéo dans Wikidata qui ont une année de publication renseignée (en ne conservant que la plus ancienne pour chaque jeu) et n’ayant pas encore d’identifiant BnF renseigné.
Dans le Flow de votre projet, ajoutez un nouveau dataset Plugin SPARQL. Renseignez l’URL du point d’accès SPARQL de Wikidata :
https://query.wikidata.org/sparql
Renseignez la requête SPARQL suivante :
SELECT ?item ?itemLabel (MIN(?year) AS ?year) {
?item wdt:P31 wd:Q7889 ; wdt:P577 ?date .
BIND(YEAR(?date) AS ?year) .
FILTER NOT EXISTS { ?item wdt:P268 [] } .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,fr" . }
}
GROUP BY ?item ?itemLabel
HAVING (?year > 1)
Récupérez les données. Profitez-en pour les manipuler, par exemple en affichant le nombre de jeux vidéo par année de publication.
Préparation des données
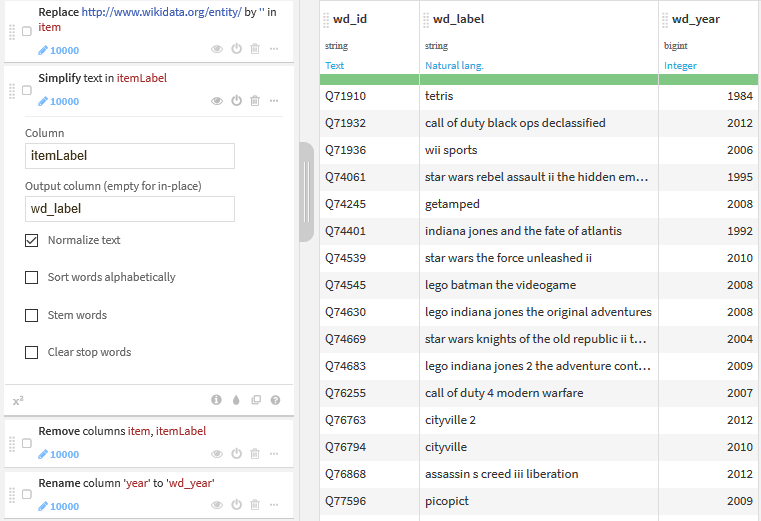
Grâce à la recette Prepare de Dataiku DSS, on prépare les données récupérées.
Les principales étapes de la préparation sont les suivantes :
- on supprime la chaîne
http://www.wikidata.org/entity/dans l’identifiant Wikidata, ce qui permet de ne conserver que la partie utile de l’identifiant, comme par exempleQ257469pour Another World ; - on normalise les libellés avec la fonction dédiée (toutes les lettres sont passées en minuscules, les accents et les caractères spéciaux sont supprimés, etc.) ;
- on renomme les colonnes pour identifier clairement que les données viennent de Wikidata.
Données de la Bibliothèque nationale de France
Import des données
De même, on importe les jeux vidéo de la BnF. Créez un nouveau dataset Plugin SPARQL, avec l’URL du point d’accès SPARQL du catalogue de la BnF :
https://data.bnf.fr/sparql
Puis avec la requête SPARQL suivante :
SELECT DISTINCT ?item ?itemLabel ?year
WHERE {
?item <http://xmlns.com/foaf/0.1/focus> ?focus ; <http://www.w3.org/2004/02/skos/core#prefLabel> ?label .
?focus <http://data.bnf.fr/ontology/bnf-onto/subject> "Informatique" ;
<http://data.bnf.fr/ontology/bnf-onto/subject> "Sports et jeux" ;
<http://data.bnf.fr/ontology/bnf-onto/firstYear> ?year .
FILTER NOT EXISTS { ?focus <http://purl.org/dc/terms/description> "Série de jeu vidéo"@fr . } .
FILTER NOT EXISTS { ?focus <http://purl.org/dc/terms/description> "Série de jeux vidéo"@fr . } .
BIND(STR(?label) AS ?itemLabel) .
}
Notez que, contrairement à Wikidata, on ne détermine qu’indirectement ce qui est un jeu vidéo dans les notices de la BnF. On est également obligé de filtrer les séries de jeux vidéo, par deux filtres différentes du fait de l’inconsistance des données de la BnF.
Préparation des données
Les libellés des jeux vidéo du catalogue de la BnF se terminent par la chaîne : jeu vidéo. Il faut l’enlever pour aligner correctement les deux jeux de données. Pour cela, dans la recette de préparation, on ajoute une étape pour remplacer cette chaîne par une chaîne vide (comme pour la préparation de l’identifiant).
Ensuite, on procède comme pour Wikidata :
- on supprime
http://data.bnf.fr/ark:/12148/cbdans l’identifiant BnF pour obtenir le format utilisé dans Wikidata, comme par exemple16770803wpour Dishonored ; - on normalise les libbelés ;
- on renomme les colonnes pour identifier clairement que les données viennent de la BnF.
Premier filtrage
On filtre les identifiants BnF qui sont déjà présents dans Wikidata, dans le but d’éviter qu’un identifiant BnF ne soit utilisé sur plusieurs éléments Wikidata.
Pour cela, on commence par récupérer les identifiants BnF utilisés dans Wikidata à l’aide d’un nouveau dataset Plugin SPARQL. On y met l’adresse du point d’accès SPARQL de Wikidata et la requête qui permet de récupérer tous les identifiants BnF utilisés :
SELECT DISTINCT ?bnf_id_to_filter WHERE { [] wdt:P268 ?bnf_id_to_filter . }
Ensuite, on joint les deux datasets bnf_video_games_prepared et bnf_ids à l’aide de la recette Join with. Le moteur par défaut de Dataiku DSS ne permet pas de faire directement une jointure externe « complète » pour filtrer d’un coup les lignes qu’on ne veut pas conserver. L’astuce consiste à faire une jointure externe « à gauche ». Dans un premier temps, on conserve toutes les lignes du premier dataset, en récupérant éventuellement les informations du second dataset si une correspondance existe (ici, on ne récupère que l’identifiant dans le second dataset) :
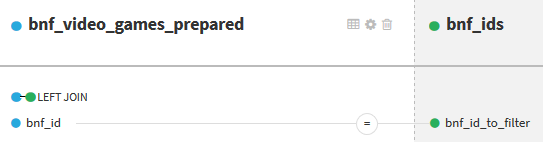
Dans un second temps, dans la partie Post-filter de la recette, on conserve les lignes du premier dataset pour lesquelles aucune correspondance n’a été trouvée, c’est-à-dire pour lesquelles la colonne bnf_id_to_filter n’est pas renseignée après la jointure.
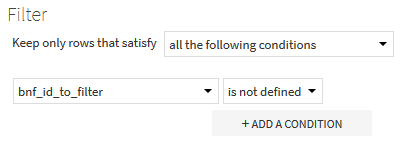
Le résultat de la recette est l’ensemble des jeux vidéo de la BnF, récupérés et préparés, filtrés de ceux ayant un identifiant déjà utilisé dans Wikidata.
Croisement des données
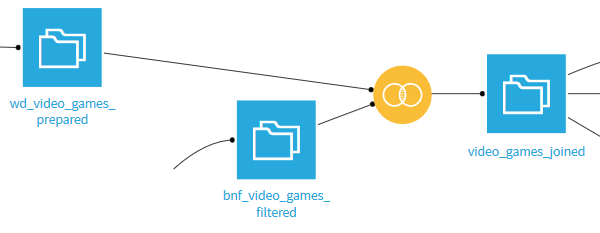
À l’aide de la recette Join with, on joint les deux datasets préparés pour ne plus en n’avoir qu’un seul. On fait une jointure interne (inner join) avec deux conditions de jointure :
- sur le libellé normalisé ;
- sur l’année de publication.
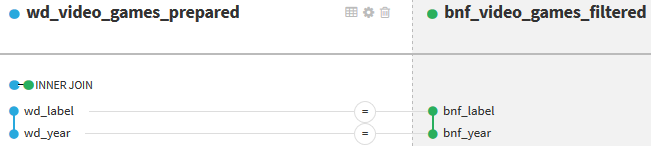
La normalisation des libellés permet de faire correspondre des libellés qui ont seulement quelques différences de forme (majuscules, accents, espaces, etc.) entre la BnF et Wikidata.
L’année de publication permet de différencier des jeux vidéo avec des titres identiques mais sortis à plusieurs années d’écart. Par exemple, il y a deux jeux nommés Doom : l’un publié en 1993 et l’autre en 2016.
Nettoyage des données
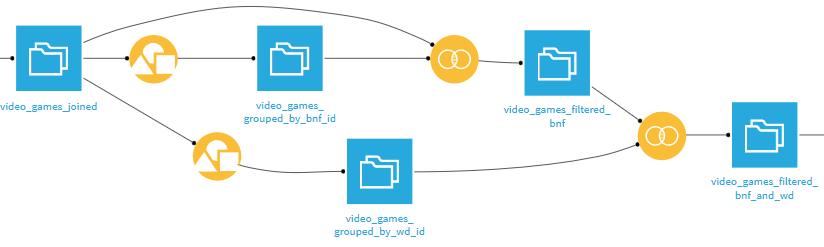
En parcourant les données, on voit qu’il y a des doublons. Par exemple, il y a plusieurs jeux vidéo Hook sortis en 1992, dont on trouve 3 identifiants dans Wikidata et 2 dans la BnF. La BnF semble également posséder 2 fiches sur le même jeu, Parasite Eve, sorti en 1998. Après vérification, il s’avère que la série n’est pas catégorisée comme telle dans le catalogue de la BnF. Plutôt que d’insérer des données incorrectes, on les filtre.
On commence par construire deux datasets, chacun représentant les jeux dont l’identifiant (respectivement Bnf et Wikidata) n’apparaît qu’une seule fois après notre croisement. Pour cela, on utilise la recette Group, en groupant les jeux vidéo par identifiant.
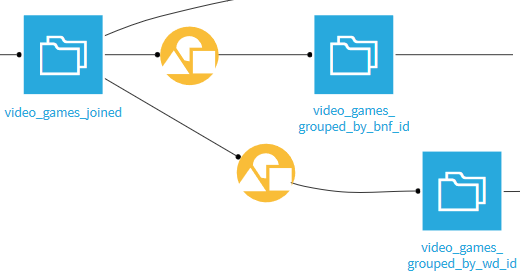
Dans les parties Post-filter de chacune des recettes Group, on ne conserve que les identifiants qui n’apparaissent exactement qu’une seule fois.
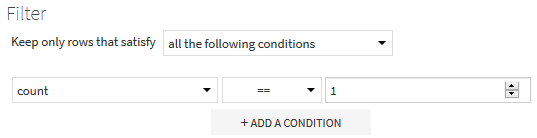
Ensuite, on fait deux jointures internes successives à partir des données croisées (video_games_joined) avec les deux datasets (video_games_grouped_by_bnf_id puis video_games_grouped_by_wd_id) que l’on vient de créer. On est alors certain que les lignes conservées ne contiennent plus de doublon dans les identifiants.
Import des données dans Wikidata
Après nettoyage, on importe les données dans Wikidata. Pour cela, on les met au format CSV attendu par QuickStatements :
- la première colonne, nommée « qid », est l’identifiant de l’élément Wikidata sur lequel on ajoute des informations ;
- les colonnes suivantes sont les informations qu’on ajoute. Dans notre cas, on a une seule colonne nommée « P268 » avec l’identifiant BnF.
Dataiku DSS permet d’exporter les données au format CSV. Il n’y a plus qu’à copier-coller le contenu du fichier exporté dans QuickStatements, ce qui donne :
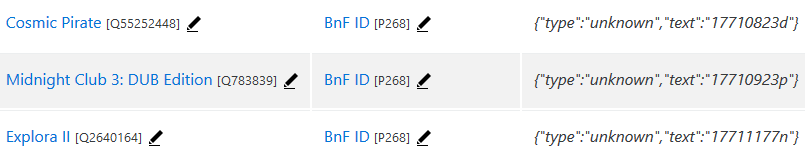
Résultats
En quelques clics, on a importé plus de 2000 identifiants BnF de jeux vidéo dans Wikidata. Toutefois, le travail n’est pas terminé !
- Le Flow est ici construit de telle façon qu’il soit réutilisable, avec la prise en compte automatique des modifications survenues dans Wikidata et dans le catalogue de la BnF. Ainsi, on pourrait imaginer l’exécuter mensuellement, afin d’obtenir de nouveaux résultats régulièrement.
- À plusieurs reprises, on a filtré de nombreux jeux, qui sont autant de cas à investiguer. On peut enrichir notre Flow pour les lister, ce qui permettra soit de les nettoyer dans Wikidata, soit de signaler d’éventuels problèmes à la BnF.
- Si on s’est ici concentré sur les jeux vidéo, on pourrait étendre le travail, par exemple aux séries de jeux vidéo et aux extensions de jeux vidéo.