 Envel Le Hir
Envel Le HirMatching BnF and Wikidata video games using Dataiku DSS
Vous pouvez lire ce billet en français : Alignement des jeux vidéo de la BnF avec Wikidata grâce à Dataiku DSS.
While the National Library of France (Bibliothèque nationale de France, BnF) collections obviously comprise numerous books, newspapers or manuscripts, they also contain elements from more recents technologies, like video games. According to its SPARQL endpoint, the BnF’s general catalogue has information on over 4,000 video games. At the same time, Wikidata has information about 36,000 video games, with only 60 linked to a BnF record in early February 2019!
In this blog post, we will see how we can improve this linking, using the software Dataiku Data Science Studio (Dataiku DSS), the objective being to correctly add the maximum number of BnF ids to video games items on Wikidata.
Dataiku DSS installation
The installation and the use of Dataiku DSS are outsite the scope of this post; however, here is some information that can be useful to start with this tool.
You can download the free edition of Dataiku DSS, which is more than enough in our case, from Dataiku website, following the instructions corresponding to your environment (for example, I use Dataiku DSS in the provided virtual machine, and access it through my favorite web browser).
You need to install the SPARQL plugin (presented in this post):
- Download the latest version (source code in zip format).
- When logged to your Dataiku DSS instance, go to the menu Administration, in the tab Plugins and then in the tab Advanced; upload the plugin.
- You will be asked to create a code environment; keep the default options and click on CREATE. The process can take a few dozens of seconds. Reload the Dataiku DSS interface by pressing F5.
On the usage of Dataiku DSS, the two first tutorials offered by Dataiku should be sufficient to understand this post.
For the next steps, it is assumed that you have created a new project in Dataiku DSS.
Data from Wikidata
Data import
From Wikidata, we import the video games which have a publication date (by keeping only the oldest one for each game) and do not yet have a BnF id.
In the Flow of your project, add a new dataset Plugin SPARQL. Enter the URL of the SPARQL endpoint of Wikidata:
https://query.wikidata.org/sparql
Then the following SPARQL query:
SELECT ?item ?itemLabel (MIN(?year) AS ?year) {
?item wdt:P31 wd:Q7889 ; wdt:P577 ?date .
BIND(YEAR(?date) AS ?year) .
FILTER NOT EXISTS { ?item wdt:P268 [] } .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,fr" . }
}
GROUP BY ?item ?itemLabel
HAVING (?year > 1)
Retrieve the data. Feel free to play with it, for example by displaying the number of video games by year of publication.
Data preparation
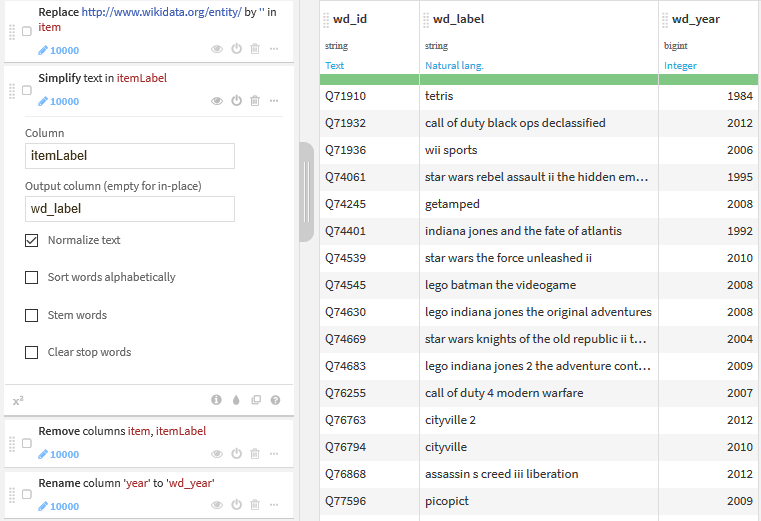
Using the Dataiku DSS recipe Prepare, we prepare the retrieved data.
The main steps of the preparation are:
- the substring
http://www.wikidata.org/entity/is removed in the Wikidata id, which allows us to keep only the useful part of the identifier, such asQ257469for Another World; - labels are normalized with the dedicated function (all letters are set to lower case, accents and special characters are removed, etc.);
- columns are renamed to clearly identify that the data comes from Wikidata.
Data from BnF
Data import
Similarly, we import video games from BnF. Create a new dataset Plugin SPARQL, with the URL of the SPARQL endpoint of the BnF catalogue:
https://data.bnf.fr/sparql
With the following SPARQL query:
SELECT DISTINCT ?item ?itemLabel ?year
WHERE {
?item <http://xmlns.com/foaf/0.1/focus> ?focus ; <http://www.w3.org/2004/02/skos/core#prefLabel> ?label .
?focus <http://data.bnf.fr/ontology/bnf-onto/subject> "Informatique" ;
<http://data.bnf.fr/ontology/bnf-onto/subject> "Sports et jeux" ;
<http://data.bnf.fr/ontology/bnf-onto/firstYear> ?year .
FILTER NOT EXISTS { ?focus <http://purl.org/dc/terms/description> "Série de jeu vidéo"@fr . } .
FILTER NOT EXISTS { ?focus <http://purl.org/dc/terms/description> "Série de jeux vidéo"@fr . } .
BIND(STR(?label) AS ?itemLabel) .
}
Note that, unlike Wikidata, what is a video game is only indirectly determined in BnF records. We also need to filter the video game series by two different filters due to the inconsistencies in the BnF data.
Data preparation
Labels of video games from the BnF’s catalogue finish by the string : jeu vidéo. We need to remove it so the two data sets can correctly match. For that, in the preparation recipe, we add a step to replace this string by an empty string (as for the preparation of the id).
Then, we proceed as for Wikidata:
- the substring
http://data.bnf.fr/ark:/12148/cbis removed in the BnF id to obtain the format used in Wikidata, such as16770803wfor Dishonored; - labels are normalized;
- columns are renamed to identify that the data comes from BnF.
First filtering
We want to filter BnF ids that are already present in Wikidata, in order to prevent a BnF id from being used on several Wikidata elements.
To do so, we start by retrieving BnF ids existing in Wikidata, using a new dataset Plugin SPARQL, with the address of the SPARQL endpoint of Wikidata and the query that returns all used BnF ids in Wikidata:
SELECT DISTINCT ?bnf_id_to_filter WHERE { [] wdt:P268 ?bnf_id_to_filter . }
Then, we join the two datasets bnf_video_games_prepared and bnf_ids using the recipe Join with. The default engine of Dataiku DSS can’t do a full outer join directly to filter out at once the lines that we want to remove. The trick is to do a left outer join. We start by keeping all the lines from the first dataset, by possibly retrieving the information from the second dataset if a match exists (here, we only retrieve the identifier in the second dataset):
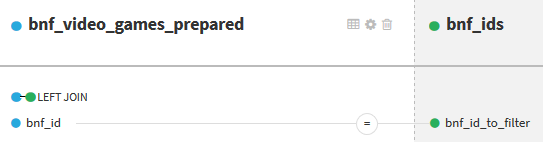
Then, in the Post-filter part of the recipe, we keep only the lines from the first dataset for which no match was found, i. e. for which the column bnf_id_to_filter is empty after the join.
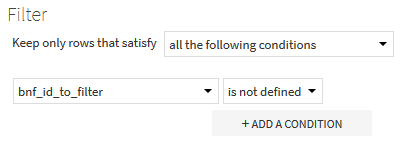
The result of the recipe is the set of video games from BnF, retrieved and prepared, filtered from those with an id already present in Wikidata.
Data matching
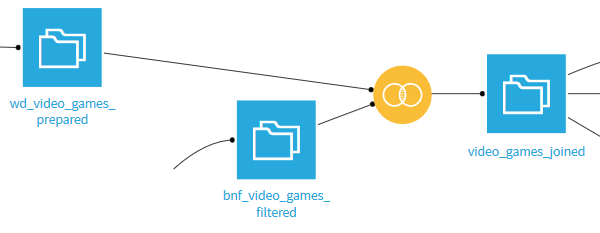
Using the recipe Join with, we combine the two prepared datasets into one unique dataset. We use an inner join with two join conditions:
- on the normalized label;
- on the year of publication.
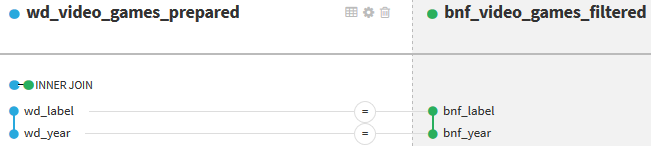
The normalization of labels allows us to match labels that have only a few differences in their format (capital letters, accents, spaces, etc.) between BnF and Wikidata.
The year of publication makes it possible to distinguish video games with identical titles but released several years apart. For example, there are two games called Doom: one published in 1993 and the other one in 2016.
Data cleaning
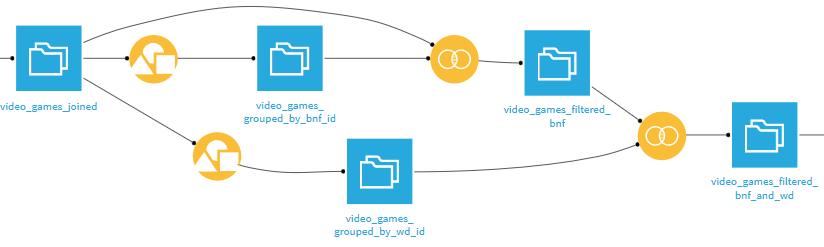
When you look at the data, you can see that there are duplicates. For example, there are several Hook video games released in 1992, with 3 ids in Wikidata and 2 in BnF. BnF also seems to have 2 records on the same game, Parasite Eve, released in 1998. After verification, it appears that the series is not categorized as such in the BnF catalogue. Rather than inserting incorrect data, we filter it out.
We start by building two datasets, each representing games having their id (respectively from BnF and Wikidata) appearing exactly one time after the matching. To do so, we use the recipe Group, grouping video games by id.
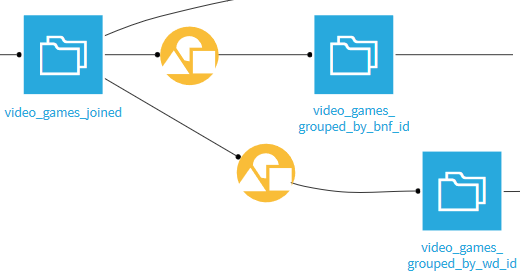
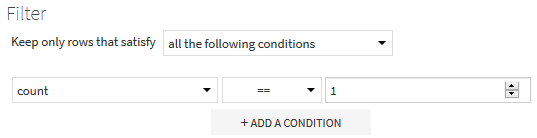
In the Post-filter part of each recipe Group, we keep only ids that appear exactly one time.
Then, we do two successive intern joins from the combined data (video_games_joined) with the two datasets (video_games_grouped_by_bnf_id and video_games_grouped_by_wd_id) that we just created. It is then certain that the retained lines no longer contain duplicates in the identifiers.
Data import into Wikidata
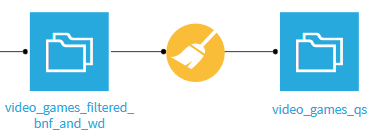
After the cleaning, we want to import the data into Wikidata. For that, we put them in CSV format, as expected by QuickStatements:
- the first column, named “qid”, is the id of the Wikidata item on which we add information;
- the next columns represent the data we add. In our case, we have only one column, named “P268”, with BnF ids.
Dataiku DSS allows you to export data in CSV format. The last step is to copy-paste the content of the exported file into QuickStatements, which gives us:
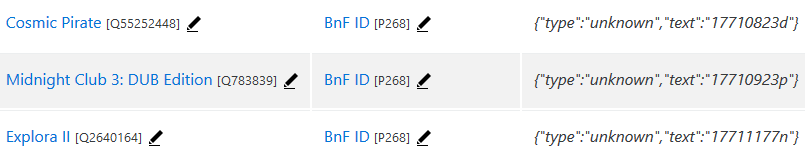
Outcomes
In a few clicks, we imported more than 2,000 BnF ids of video games into Wikidata. However, the work is not finished!
- The Flow is constructed in such a way that it can be reused, with automatic integration of changes in Wikidata and the BnF catalogue. Thus, one could imagine running it monthly, in order to obtain new results regularly.
- On several occasions, games have been discarded; they are cases that need to be investigated. We can expand our Flow to list them, which will allow us to clean them in Wikidata, or to report potential issues to BnF.
- In this post, we have focused on video games, but we could extend the scope of our work, for example to video game series or to video game addons.